Install Hadoop 2.5.1 on Windows 7 - 64Bit Operating System
This post is about installing Single Node Cluster Hadoop 2.5.1 (latest stable version) on Windows 7 Operating Systems.Hadoop
was primarily designed for Linux platform. Hadoop supports for
windows from its version 2.2, but we need prepare our platform
binaries. Hadoop official website recommend Windows developers to use
this build for development environment and not on production, since
it is not completely tested success on Windows platform. This
post describes the procedure for generating the Hadoop build for
Windows platform.
Generating Hadoop Build For Windows Platform
Step 1:Install Microsoft Windows SDK 7.1
Step 1:Extract Hadoop
Generating Hadoop Build For Windows Platform
Step 1:Install Microsoft Windows SDK 7.1
- In my case, I have used Windows 7 64 bit Operating System. Download Microsoft Windows SDK 7.1 from Microsoft Official website and install it.
- While installing Windows SDK,I have faced problem like C++ 2010 Redistribution is already installed. This problem will happen only if we have installed C++ 2010 Redistribution of higher version compared to the Windows SDK.
- We can solve this issue by either not installing the C++ 2010 Redistribution by unchecked the Windows SDK on custom component selection or uninstalling from Control Panel and reinstalling the C++ 2010 Redistribution via Windows SDK again.


- I recommend everybody to download Oracle Java JDK7 and install JDK at C:\Java\ instead of default path C:\Programming Files\Java\. Since this default path contains invalid space character between “Programming” “Files”.

- Now we need to configure JAVA_HOME Environment Variable with value “C:\Java\jdk1.7.0_51”. If we have already installed Java at it's default path (C:\Programming Files\Java\). We need to find its 8.3 pathname with the helpof “dir /X” command from its parent directory. The sample 8.3 pathname will look like "C:\PROGRA~1\Java\jdk1.7.0_51".

- Finally we need to add Java bin path to PATH enviroment variable as “%JAVA_HOME%\bin”.






- Download latest Apache Maven from its official website and extract to C:\maven. Configure the M2_HOME Enviroment Variable with maven home directory path “C:\maven”.

- Finally add the maven bin path to PATH Environment variable as “%M2_HOME%\bin".



- Download binary version of Protocol Buffer from it official website and extract it to “C:\protobuf” directory and add this path to PATH Environment Variable.


- Download the latest version of Cygwin from its official website and install at "C:\cygwin64" with ssh, sh packages.

- Finally add the cygwin bin path to PATH environment variable.



- Download the latest cmake from its official website and install it normally.
- Add the “Platform” environment variable with the value of either “x64” or “Win32” for buildin on 64-bit or 32-bit system.(Case-sensitive)
- Download the latest stable version of Hadoop source from its official website and extract it to “C:\hdc”. Now we can generate Hadoop Windows Build by executing the following command on Windows SDK Command Prompt.
mvn package -Pdist,native-win -DskipTests -Dtar
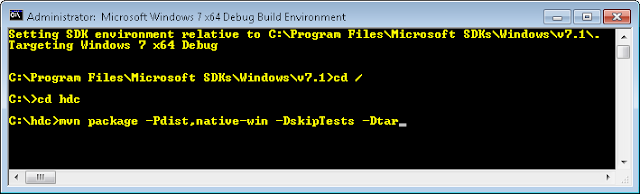
- The above command will run for approx 30 min and output the Hadoop Windows build at C:\hdc\hadoop-dist\target” directory.

Step 1:Extract Hadoop
- Copy the Hadoop Windows Build tar.gz file from “C:\hdc\hadoop-dist\target” and extract at “C:\hadoop”.
- Edit the “C:\hadoop\etc\hadoop\hadoop-env.cmd” file and add the following lines at the end of the file. The following lines will configure the Hadoop and Yarn Configuration Directories.
set HADOOP_PREFIX=c:\deploy set HADOOP_CONF_DIR=%HADOOP_PREFIX%\etc\hadoop set YARN_CONF_DIR=%HADOOP_CONF_DIR% set PATH=%PATH%;%HADOOP_PREFIX%\bin
- Edit the “C:\hadoop\etc\hadoop\core-site.xml” file and configure the following property.
<configuration> <property> <name>fs.default.name</name> <value>hdfs://0.0.0.0:19000</value> </property> </configuration>
- Edit the “C:\hadoop\etc\hadoop\hdfs-site.xml” file and configure the following property.
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
- Edit the “C:\hadoop\etc\hadoop\mapred-site.xml” file and configure the following property.
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:54311</value> </property> </configuration>
- Create a tmp directory as “C:\tmp”, where “C:\tmp” is the default temperory directory for Hadoop.
- Execute the “C:\hadoop\etc\hadoop\hadoop-env.cmd” file from the Command Prompt to set the Environment Varibales.
- Format the file sytem by executing the following command before first time usage.
%HADOOP_PREFIX%\bin\hdfs namenode -format
- Execute the following command to start the HDFS.
%HADOOP_PREFIX%\sbin\start-dfs.cmd
- Open the browser with address http://localhost:50070, this page will display the currently running nodes and we can browse the HDFS also on this portal.

when I run the mvn package etc I get Missing ProjectException
ReplyDeleteon line maven help unhelpful
Hey thanks for the guide really helped me a lot!
ReplyDeleteI still encountered some problems, so I thought I should share my solutions.
1) "[ERROR] Failed to execute goal org.apache.maven.plugins:maven-javadoc-plugin:2.8
.1:jar (module-javadocs)"
Since the error is with the javadoc plugin I skipped it by specifying -Dmaven.javadoc.skip=true
2) In the "Configuring Hadoop for Single Node" step 2 the line "set HADOOP_PREFIX=c:\deploy" should probably be "set HADOOP_PREFIX=c:\hadoop".
3) in the same Step as above be careful to not just copy and past the text from the guide the blank characters in the end of each line prevented me from executing "%HADOOP_PREFIX%\bin\hdfs namenode -format "
Hi,
ReplyDeleteI am getting the following errors:
1. The requested profile "dist" could not be activated because it does not exist.
2. The goal you specified requires a project to execute but there is no POM in this directory
Pl. can some one help me how can I solve this. TIA
For the people with the error try this:
ReplyDeletemvn clean package -Pdist -Dtar -Dmaven.javadoc.skip=true -DskipTests -fail-at-end -Pnative
This is very helpful. Two questions - will this work with JDK 1.8.0? Secondly (using JDK 1.8.0), I am getting this error: [ERROR] Failed to execute goal org.apache.maven.plugins:maven-antrun-plugin:1.7:
ReplyDeleterun (make) on project hadoop-pipes: An Ant BuildException has occured: exec returned: 1
Book Tenride call taxi in Chennai at most affordable taxi fare for Local or Outstation rides. Get multiple car options with our Chennai cab service
ReplyDeletechennai to kochi cab
bangalore to kochi cab
kochi to bangalore cab
chennai to hyderabad cab
hyderabad to chennai cab
This comment has been removed by the author.
ReplyDeleteXmedia Solution
ReplyDeleteXmedia Solution
Xmedia Solution
Xmedia Solution
Perhaps your child has been behaving weirdly recently, and you suspect drug use or you have a drug test coming up and want to know if you are clean. Thanks to medical advances, you no longer need to run to a hospital to take a urine drug test. It is now possible to do it from the comfort of your own home. Cannabis, unlike other drugs, stays in your system longer for up to seven days if you wait for it to pass naturally. Let’s take a closer look at each test to differentiate between them. Urine tests are non-invasive and simple to perform as all you have to do is give a sample of your urine. Visit: https://www.urineworld.com/
ReplyDeleteMobile Prices Bangladesh that is great web
ReplyDeletebest payroll outsourcing companies
ReplyDeletehttps://www.royaltykitten.com/sphynx-cats-for-sale/
ReplyDeletehttps://www.royaltykitten.com/sphynx-cat-for-sale-near-me/
https://www.royaltykitten.com/sphynx-kitten-for-sale/
https://www.royaltykitten.com/kittens-for-sale-near-me/
ReplyDeletebad sperm shape
male infertility causes
smoking
ReplyDeleteGamsat organic chemistry
CBSE organic chemistry
IIT organic chemistry
Organic Chemistry Notes
I think this post is going to be helpful for many people.bus rental Dubai Dubai airport transfer
ReplyDelete
ReplyDelete청주콜걸
제천콜걸
삼척콜걸
충북콜걸
삼척콜걸
전남콜걸
전남콜걸
대전콜걸
ReplyDelete세종콜걸
광주콜걸
서울콜걸
울산콜걸
인천콜걸
부산콜걸
대구콜걸
This comment has been removed by the author.
ReplyDeleteDo you have guide for windows 8 ?
ReplyDeleteBus Rental Ajman
You have explained well for windows 7
ReplyDeleteBus Rental Ajman
I learned something new from your article. Thanks for sharing
ReplyDeleteBus Rental Sharjah
Thank you for sharing such valuable information! Your writing style is engaging, making complex concepts easy to understand. Great job!
ReplyDeleteBus for rent\
I want to express my appreciation for your commitment to quality. Your work sets a high standard for content creators.
ReplyDeleteMarble in Dubai
This article is a testament to the author's expertise and dedication to delivering value. I'm grateful for the insights shared in this comprehensive piece.
ReplyDeleteMini Bus for rent