Distributed Database Management System
Distributed Computing
There are several autonomous computational entities, each of which has its own local memory.These entities communicate with each other by message passing.
Typical properties of distributed systems.

A computer program that runs in a distributed system is called distributed program and distributed programming is the process of writing such programs
A distributed system may have common goal, such as solving a large computational problem. Alternatively each computer may have its own user with individual needs and the purpose of the distributed system is to coordinate the use of shared resources or provide communication services to the users.
There are several autonomous computational entities, each of which has its own local memory.These entities communicate with each other by message passing.
Typical properties of distributed systems.
- The system has to tolerate failures in individual computers.
- The structure of the system(network topology, network latency, number of computers) is not know in advance, the system may consist of different kinds of computers and network links. and the system may change during the execution of a distributed program.
- Each computer has only a limited, incomplete view of the system. Each computer may know only one part of the input
Parallel computing may be seen as a particular tightly coupled form of distributed computing and distributed computing may be seen as a loosely coupled from of parallel computing. In other words, parallel computing has homogeneous nodes and distributed computing has heterogeneous nodes to perform a common task.
- In parallel computing, all processors may have access to a shared memory to exchange information between processors
- In distributed computing, each processors has its own private memory (distributed memory). Information is exchanged by passing message between the processors.

Figure(a) is a schematic view of a typical distributed system as usual,the system is represented as a network topology in which each node is a computer and each line connecting the nodes is a communication link.
Figure(b) shows the same distributed system in more detail, each computer has its own local memory and information can be exchanged only by passing message from one node to another by using the available communication links.
Distributed Database
Distributed database is logically related database, and distributed over a network.A distributed database is a database in which storage devices are not all attached to a CPU, controlled by a distributed database management system.It may be stored in multiple computers, located in the same physical location or may be dispersed over a network of interconnected computers. Unlike parallel system, in which the processors are tightly coupled and constitute a single database system, a distributed database system consists of loosely-coupled sites that share no physical computers.
Here along with the processing nodes with related databases are shown in the above picture
Distributed Database Management System = [ System managing the Distributed Database + Meeting Distributed Transparency ]
We can easily add the new processing and distributed notes. But in centralized database, there is a limitation on adding nodes. If the limit is 3, we can't add more than 3 processing sites.
But in distributed database we can expand by
- Add more locations
- Add more processors per site
- Keeping track of data
- Distributed query processing
- So we need to split the query as sub query.
- Distributed transaction management
- Replication data management
- Distributed data recovery
- If any particular link failures or site failures, we still need to recovery from that.
- Security
- Right person with right authority should access the data.
- Every node should give same result on authority.
- Catalog management
- Global catalog - Gives information about what is located at each element.
- Local catalog - Gives information about how the data are stored and related.
So user need not aware of distributed databases.
Advantages of Distributed Database
- Transparency
- Network Transparency
- Location Transparency - It should enable to execute any query from everywhere using the same command.
- Naming Transparency - It should have unambiguous access, once name has been specified.
- Replication Transparency - It should replicate to other servers without knowing to user.
- Fragmentation Transparency
- Horizontal Fragmentation - Fragmented by upper fragment and lower fragment.
- Vertical Fragmentation - Fragmented by right fragment and left fragment.
- The main thing is user should not aware of this fragmentation transparency .
- Increased Reliability and availability
- Reliability - Probability of system working at a particular point of time.
- Availability - Probability of system working continuously during a particular time interval.
- Improved Performance
- Comparing with centralized, in centralized database every query goes to centralized database so the database server gets bottle neck problem.
- But in distributed system for the single request, every working nodes will collaboratively work and produce the expected data to the requested data by parallel.
Horizontal fragmentation is the fragmentation of the data by upper fragment and lower fragment. This splits relation by assigning each tuple of relation to one or more fragments.
Example:
Consider the schema of Employee table as Employee(Id, Name, Age, Phone, Address, Email Id, Department). And where we can store DB1 for Sales department, DB2 for R&D department,DB3 for Marketing department and DB4 for Technical department.

So the condition used to fragment is guard condition :
SELECT Id,Name,Age,Phone,EmailId,Department FROM Employee where Department='RD'
So the condition used to fragment is guard condition :
This is called complete horizontal fragmentation by department='sales' , department='marketing', department='technical', department='RD'. So collection of all horizontal fragmentation gives entire relation.
Entire Relation = F1 U F2 U F3 U ......Fn
Vertical Fragmentation
Vertical fragmentation is the fragmentation of the data by right fragment and left fragment. This splits relation by assigning
each attribute of relation to one or more fragments.There has to some common attribute between the different fragmentation. This common attribute will help us to reconstruct the relation using table join.
Example:
Consider the schema of Employee_personal table as Employee_personal(Id, Name, Age, Phone, Address) at DB1,schema of Employee_official table as Employee_official(Id, Email, Department) at DB2, schema of Employee_attendance table as Employee_attendance(id,date,status) at DB3 and schema of Employee_other_details table as Employee_other_details(id,other_details) at DB4.


The complete vertical fragmentation : L1,L2,L3 are the attributes of the fragmentation F1,F2,F3 attributes respectively. The intersection of any fragmentation should produce the primary key.(i.e F1 n F2 = PK(R))
Entire Relation = F1 U F2 U F3 U ......Fn(Vertical Fragmentation)
Mixed Fragmentation / Hybrid Fragmentation
It is the combination of Horizontal Fragmentation and Vertical Fragmentation.
Example
Consider the below
DB1 has Official table for Sales department as Official(id, email,department='sales'),
DB2 has Official table for Technical department as Official(id, email, department='technical'),
DB3 has Official table for Research department as Official(id, email, department='research').
DB4 has Project table as Project(id, name, address, phone, age).
Allocation of Fragmentation to Site as follows
Fragmentation F1 lies at DB1 at Site1,
Fragmentation F2 lies at DB2 at Site2,
Fragmentation F3 lies at DB3 at Site3,
Fragmentation F4 lies at DB4 at Site4
This allocation schema defines where fragmentation are location. So the DB designer should now where the original exists of the relations.
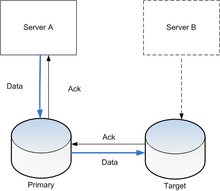
Data Replication
Data Replication is the process of storing same date at multiple servers with Master/Slave relationship between original and copy. When the data is replicated between database servers, so that the information remains consistent throughout the database system.
Full Replication- Every data element is replicated to some or other site but the problem is over head in making the changes consistent in other site.
No Replication- We don't have the copy of any data any where, Here problem is availability and reliability.
Partial Replication- Here not entire data are replicated but some data are replicated.
Advantages of Replication:
Availability- failure of site containing relation r does not result in unavailability of r is replicas exist.
Parallelism- queries on r may be processed by several nodes in parallel.
Reduced data transfer- relation r is available locally at each site containing a replica of r.
Disadvantages of Replication:
Increased cost of updates to achieve each replica must be updated and Increased complexity of concurrency controls.
Note: We should apply any concurrent control operation only on primary copy replica.


Comments
Post a Comment